La familia de chips TPU (Tensor Processing Unit) va a entrar en su octava generación y Google, su progenitora, lo ha celebrado preanunciando dos modelos inaugurales en la conferencia Google Cloud Next en Las Vegas. No estarán disponibles hasta finales de año, pero desde ya hacen más revuelo que los anteriores. Uno de ellos, bautizado como TPU 8t, tiene como objetivo el entrenamiento de modelos `de frontera´ mientras su hermano TPU 8i está diseñado para ocuparse de cargas de inferencia en los agentes de IA, en las que concurran dos exigencias: baja latencia y mucha memoria. Esta escisión entre training (de ahí la t) e inference (la i), marca una ruptura en el paisaje establecido.

Aunque faltan meses para su disponibilidad, el preanuncio ha tenido consecuencias inmediatas. Para empezar, ejerce presión sobre AWS, que inició esta carrera con sus chips Graviton, con los que los de Google comparte ciertos rasgos y que de año en año van ganando competitividad. Por otro lado, Nvidia ha acogido con flema la noticia, un riesgo menor, que ya no es potencial.
Como Google no da puntada sin nudo, se ha asegurado desde ya sendos contratos con Meta y Anthropic que se sumarán a su demanda interna. La primera, que ha derrochado dinero en tantas aventuras, se ha resignado a no contar con una TPU propia, por lo que comprará una cantidad de los de Google. Pero como tampoco quiere casarse, ha firmado en paralelo por varios millones de dólares con AWS, aparte de mantenerse fiel a Nvidia como proveedor de GPU (graphic processing units).
AWS, a su vez, acaba de ampliar la inversión en Anthropic, que concretará facilitando a esta el uso de los Graviton en su nube. Queda por enumerar el papel de Cerebras, especialista nata en el diseño de aceleradores para inferencia, que suministra bajo demanda a AWS. Como se ve, la partida de naipes reúne a numerosos jugadores cuya demanda de chips para IA, en una u otra modalidad, es insaciable. Y no se han citado aquí las neoclouds, con historia propia.
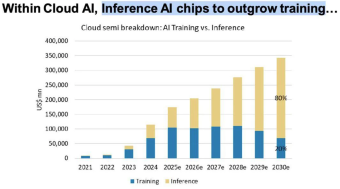
¿A qué se debe tanto trasiego? A que los agentes de IA, que están en boca de todos, elaboran una respuesta más precisa e informada a las cuestiones específicas de los usuarios, que en esto consiste “inferir” información en base a los datos que ya se tienen, volviendo repetidamente sobre ellos, y no tanto a bucear en nuevas colecciones de datos. Esto significa que los chips agénticos tardan más tiempo en responder y por lo tanto requieren una estructura algo distinta de los que están orientados a tareas de aprendizaje: una proporción más alta de memoria y menos capacidad de computación.
Si hasta ahora los chips gráficos que hicieran la fortuna de Nvidia han sido protagonistas indiscutibles de la inteligencia artificial, ahora vuelven por sus fueros las clásicas CPU (central processing units) en los centros de datos, como mínimo para complementar las GPU.
Google ha formalizado este uso distintivo de los chips para IA, para inferencia o para aprendizaje, con el anuncio de sus nuevos TPU en su convención Google Cloud Next. Como es obvio comparten muchas características. El TPU 8t está pensado para centros de datos destinados al entrenamiento de modelos de lenguaje, como el Gemini 3 de la propia Google u otros de la competencia, en conjuntos de hasta 9.600 procesadores, donde la prioridad es la potencia de cálculo. En su caso, el TPU 81i se dedica a inferir datos, tarea a la que contribuye con mucha más memoria de alta velocidad (HBM), hasta 332 TB, frente a los 43 TB de la anterior generación.
Google proyecta vender un total de 4,3 millones de TPU este año (de la séptima generación ahora en producción) y pasar a más de 35 millones en 2028 con la octava generación. Sólo el compromiso de Anthropic ya representa un millón de unidades y otras tantas están adjudicadas a Meta, con una potencia global de unos 3,5 GW acumulados en los TPU previstos en 2027.
Según ha mencionado Broadcom, que ha compartido con Google el diseño de la siete primeras generaciones, la facturación de Google a Anthropic será de unos 21.000 millones de dólares en 2026 y se doblará el año que viene. De más está decir que Google no está sola en un páramo: ha de contar con la competencia de los Inferentia y los Trainium, de AWS, además de los menos notorios Maia, de Microsoft. Se sabe que Anthropic, con el viento a favor, está desarrollando el suyo. En total, el mercado de estos chips de inferencia, según la consultora TrendForce, puede alcanzar los 118.000 millones de dólares en 2033.
Thomas Kurian, CEO de Google Cloud, aseguró en Las Vegas que las necesidades en inteligencia artificial evolucionan “y por tanto construimos los chips y los sistemas para inferencia de forma distinta a los destinados a entrenamiento”. Ambos chips, dijo, estarán disponibles para compra o en alquiler a través de la oferta comercial de Google Cloud.
Amin Vahdat, vicepresidente de Google y responsable de la infraestructura IA de la compañía, señala que los desarrollos de estos chips empezaron hace dos años, “cuando llegamos a la conclusión de que un único tipo de chip no sería suficiente”. Hace un mes, Nvidia anunciaba que incorporará en sus Rubin una CPU y el software de Groq, una de sus adquisiciones recientes.
Mark Lohmeyer, otro vicepresidente de Google Cloud, aseguró en Next 2026 que “lo que realmente quieren los clientes es reducir la latencia en las tareas de inferencia”, el tiempo de respuesta. “Una simple consulta a un agente IA genera entre 20 y 50 veces más transacciones de inferencia que una pregunta a una herramienta conversacional (chatbot), porque los agentes realizan numerosas acciones internas antes de generar una respuesta”.
Aparte de dar una respuesta más rápida, las nuevas TPU también consumen menos energía que sus antecesores otra de las grandes preocupaciones de los dueños y clientes de centros de datos. Para que los nuevos sistemas de IA sean energéticamente más eficientes, Google ha introducido la red Virgo, con el rol de unificar múltiples centros de datos y hacer que funcionen como uno solo, aplicando en esto lla filosofía de “campus-as-a-computer”. “A medida que crecen exponencialmente los parámetros de modelos fundacionales, las redes tradicionales están llegando al límite”; de ahí el diseño de la red Virgo.
Esta explosión de la demanda de computación para IA la está experimentando Google de primera mano. “Nuestros modelos de Google Cloud están procesando más de 16.000 millones de tokens por minuto para nuestros clientes, frente a los 10.000 millones del último trimestre”, publicó en X el CEO de Alphabet, Sundar Pichai.
La media de usuarios mensuales de Gemini Enterprise de pago ha aumentado un 40% en el primer trimestre, precisó Pichai. Para dinamizar aún más la IA agéntica, Google Cloud ha dado a conocer la creación de un fondo de 750 millones de dólares que dedicará sus recursos a incentivar a los 120.000 partners de su ecosistema que trabajan con la IA agéntica.
Mientras tanto, Nvidia continúa siendo el líder indiscutible de los sistemas IA, tanto de aprendizaje como de inferencia, y se calcula que tiene alrededor del 80% de un mercado en plena expansión. Pero no cabe duda de que estos procesadores, puestos a punto por Google y Amazon y otros de los nuevos competidores – no olvidar los suministradores chinos – ponen en jaque a Nvidia, como también a AMD e Intel.
Sin embargo, al fundador y CEO de Nvidia, Jensen Huang, tal vez le incomode la presencia de Broadcom en este espacio, pero dice no estar preocupado por la competencia, una interesantísima conversación con el podcaster Dwarkesh Patel
“Nvidia no hace procesadores tensores; construimos sistemas de cálculo de alta velocidad y nuestros productos sirven tanto para la dinámica molecular como para la cromodinámica cuántica, el tratamiento de datos estructurados y no estructurados, la dinámica de fluidos, la física de fluidos y, además, sirven para la IA”, explica en el podcast de Patel.
Huang nunca ha ocultado que su fortaleza reside no sólo en los chips gráficos, sino en su software CUDA, con millones de aplicaciones que se han ido desarrollando a lo largo de los últimos veinte años, y, por si no fuera poco, con la inversión y apoyo de muchas empresas, que pasan a ser clientes cautivos de los sistemas y software de la compañía, a veces a cambio de invertir en esas empresas.
La capacidad de Nvidia de acaparar chips de memoria de alta velocidad de SK Hynix, sin mirar el precio, gracias a los generosos márgenes de que disfruta, es otro factor importante de su éxito y su capitalización bursátil (o lo ha sido hasta ahora), así como que Nvidia no compite en el desarrollo de modelos. Enfatizó que todo el software que desarrolla su compañía es de código abierto y cubre las necesidades específicas de sus clientes.
Las TPU concebidas por Google presentan elocuentes ventajas para los clientes de su nube, porque todo el sistema está pensado y optimizado para sus infraestructuras. También lo son para otros cultores de la IA que, por sus buenas razones, no quieren ser absolutamente dependientes de Nvidia. Esta es otra clave de la jugada: NVidia abastece a todo el mundo y sus procesadores no pueden diseñarse totalmente a medida. Tal como se ha ido configurando el mercado, el ecosistema de IA está condicionado en mayor o menor medida por la posición de liderazgo que ha adquirido Nvidia. Google, con su juego a múltiples bandas, tiene turno de palabra.
[informe de Lluís Alonso]