El volumen de datos que se generan y almacenan en todo el mundo es ingente. Un problema que los sistemas de almacenamiento actuales no pueden resolver: hace dos años ese volumen equivalía a 45 zettabytes, magnitud que nubla la vista sólo con contar ceros: 1. 000. 000. 000. 000. 000. 000. 000. bytes o un billón de gigabytes ordinarios. Lo peor es que su crecimiento es exponencial y en algún momento podría ser catastrófico: la consultora IDC ha estimado que alcanzarán los 175ZB en 2025. Tecnologías como big data e inteligencia artificial, así como el desarrollo de las biociencias, añaden una aceleración que excede de lejos la capacidad de los soportes actuales, sean magnéticos, digitales u ópticos.

Pierre Crozet, Erfane Arwani y Stéphane Lemaire
Puede que la solución (parcial) al problema no proceda finalmente de la electrónica sino de la biología. Una empresa francesa fundada el año pasado, Biomemory – impulsada en común por La Sorbona y el CNRS (homólogo del CSCI español) junto con inversores privados – ha acometido el desarrollo de un dispositivo que llama DNA Drive y que describe como un contenedor tonto (sic) para almacenar permanentemente archivos y bibliotecas robotizadas, llamado “frío” porque muy raramente esa información se consulta, pero ocupan espacio y no puede borrarse. Mayoritariamente, esos datos residen en cintas magnéticas cuya vida oscila entre 15 y 25 años; copiarlos en soportes modernos sería costoso y garantiza perennidad.
En consecuencia, los científicos se han puesto a investigar la viabilidad de nuevos soportes. Uno de ellos, el más sorprendente, busca sintetizar cadenas de ADN en las que almacenar datos: cualquier tipo de dato. En la universidad de Harvard se ha diseñado un método para insertar los datos de un vídeo en un organismo vivo, una bacteria E.coli con la posibilidad de recuperarlos después de varias generaciones de reproducción de la bacteria. A partir de ahí se han formulado hipótesis difíciles de imaginar a priori.
El fundamento sobre el que se apoya la innovación de Biomemory es, por tanto, el ADN que contiene las instrucciones genéticas de todo organismo vivo. Los fundadores de la empresa son los biólogos Stéphane Lemaire y Pierre Crozet, quienes han inventado un método y un algoritmo para la codificación y recuperación de datos que funciona sobre una intuición teórica atribuida al físico Richard Feynman [el mismo que planteó la hipótesis de un ordenador cuántico] en 1959.
Ha habido algunos momentos importantes sobre la misma hipótesis. En 2012 – también en Harvard – codificaron en una porción de ADN el contenido de un libro de 300 páginas, cuyo autor fue uno de los científicos que contribuyeron al proyecto Genoma Humano.
Se trata de convertir los 0 y 1 de la informática (información binaria) al código cuaternario del ADN, en el que las letras A, C, G y T representan nucleótidos que son la base del material genético. Con el fin de abaratar su coste – que hoy sería imposible – son organizados como secuencias que no pueden ser manipuladas con ninguna otra finalidad.
El archivo binario es convertido en una secuencia de ADN, sintetizada y agrupada en plásmidos, luego amplificada biologicámente, extraída y almacenada. La lectura se realiza mediante una secuenciación y conversión a archivo binario
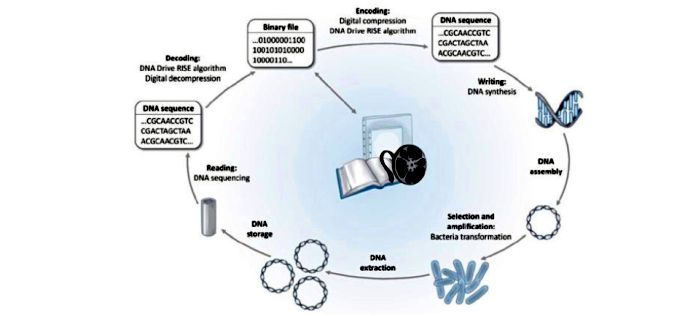
Con esta somera descripción, un profano ya puede encajar el argumento inicial de la conversación con Lemaire: las copias de la información almacenada gracias al ADN se podrían conservar intactas “durante varias decenas de miles de años”, a diferencia de los soportes actuales (cintas magnéticas, discos duros, DVD o memorias de estado sólido), cuya duración media es de unos pocos años. Los ejemplos que describe son increíblemente compactos. “Una vez extraídas, las moléculas que contienen los datos son purificadas, liofilizadas e introducidas en diminutas cápsulas de acero inoxidable con atmósfera inerte”, apostilla su colega Crozet. Se suelda con láser la cápsula, de tal manera que “conseguimos proteger el ADN de los tres elementos que podrían dañarlo: agua, oxígeno y luz”.
La lectura de los datos almacenados, con un secuenciador estimulado por el algoritmo y su recuperación posterior – aseguran ambos fundadores – tiene un 100n de fidelidad. A temperatura ambiente, esta tecnología no consume energía, a diferencia de los sistemas digitales que requieren enfriamiento. Este es un punto crucial: los centros de datos existentes consumen el 2% de la electricidad mundial. El problema por resolver es, cómo no, el coste de su codificación, que debería reducirse 1.000 veces para compararse con las tecnologías comerciales, tercia en la charla con un grupo de periodistas europeos el emprendedor Erfane Arwani, que representa a los inversores que respaldan el proyecto.
Se trata, pues, de una tecnología en desarrollo con tres cualidades: es compacta, energéticamente neutra y de larga vida. Aunque por ahora es comercialmente inviable. El coste de codificar y decodificar los datos que contiene una cápsula sería actualmente de 900 euros por megabyte. Los cálculos oficiosos predicen que en 2030, sintetizar ADN para este propósito podría costar en 2030 un dólar por terabyte.
Pese a esta evidente dificultad, o tal vez por eso mismo, Biomemory no está sola en esta búsqueda. La industria de las TI trabaja en esta forma de combinación entre equipos que proceden de las ciencias de la vida y de la ciencia de los datos. Algunos nombres de fuste, como Microsoft, Seagate, Western Digital y Dell, han dado pasos en la misma dirección y forman parte la DNA Storage Alliance.
[publicado en La Vanguardia el 16/10]