
Esta es la segunda parte del post de ayer, que presentaba varias propuestas cuyo común denominador es la gestión de los datos corporativos mediante herramientas y plataformas que siguen casuísticas variables según el entorno de que se trate. El origen de la crónica es, nuevamente, la participación de este blog como miembro español del grupo IT Press Tour, formado por una docena de periodistas europeos que regularmente visitan empresas del Silicon Valley [en esta ocasión orientadas a aplicaciones; otras centradas en la infraestructura]. Normalmente, dejan como lección un contraste con ciertos mitos circulantes en España acerca de cómo funcionan las startups californianas.

AtScale. Los fundadores de esta empresa aportan una amplia experiencia en el segmento de business intelligence y exponen sus ideas con claridad. Su espacio en la gestión de datos es lo que se conoce como data preparation, consistente en conectar con distintas fuentes de información y adaptar los datos para trabajar en entornos distintos. Si el business plan de AtScale funciona, podría ser uno de esos ´pelotazos` que en Estados Unidos llaman – con demasiada frecuencia – the next big thing: el binomio Hadoop + business intelligence. Ya se verá.
Bruno Aziza, cofundador y CMO de esta compañía creada por veteranos de Yahoo, explica así su punto de vista: «muchos usuarios de plataformas de BI, aquellos que piensan desde la óptica del negocio, acaban frustrados con tecnologías que no les permiten acceso o en las que no encuentran la agilidad, rendimiento y seguridad que se les promete para llevar a cabo su trabajo». AtScale se propone actuar como enlace entre los usuarios y el personal de TI, de forma que, al reducir la distancia entre los dos mundos se consiga mayor agilidad a la hora de crear informes (o de adaptar los existentes). Por otro lado, sacar el mayor partido posible a las herramientas de BI como Tableau, Microstrategy o Qlik Y para todo ello, apoyarse en Hadoop, como sistema más económico y dinámico que otras arquitecturas, aunque no necesariamente friendly.

Bruno Aziza
En realidad, la plataforma de AtScale es un despliegue orgánico que surge, por un lado, de Big Data, y por otro de la perentoria necesidad de analizar los datos relevantes para la inteligencia del negocio. El problema, tal como lo describe Aziza, es que las soluciones BI que hay en el mercado son altamente complejas, y necesitan involucrar personal cualificado para ocuparse de un proceso que incluye traducir – es decir, preparar – los datos manualmente desde su origen. Esto, además, genera múltiples copias de los datos y lleva asociado un modelo rígido, por lo que cualquier cambio, además de su sensibilidad intrínseca, requiere mucho tiempo de implementación.
Tal vez la descripción de Aziza peca de enfatizar los problemas para llevar a su terreno, que no es otro que romper con la rigidez a través de un modelo de tres capas: 1) copiar los datos en Hadoop (económico, flexible y escalable), 2) recolectar y enriquecer la información en bruto con su propia plataforma, basada en cloud y 3) enviarla procesada a cualquiera de las herramientas estándar de BI (Tableau, Qlik, Microstrategy, Cognos, Excel…).
En esencia, la plataforma AtScale se encarga de ´interceptar` las consultas a las fuentes de datos y enriquecerlas visualmente, a la vez que acelera el rendimiento general. Esta forma de actuación – llegado a este punto, Aziza acelera – aporta flexibilidad, modularidad, modelización en tiempo real […] sin que los sistemas de TI pierdan el control y sin sacrificar la consistencia de los datos. Los usuarios, por su parte, tendrán mayor independencia para generar sus propios informes. Mensaje recibido.
David Mariani, cofundador y CEO de AtScale [fue VP de la unidad Data User & Analytics de Yahoo, donde se originó Hadoop] sostiene que «la industria se dirige a una transformación masiva: las empresas necesitan una solución que permita a los usuarios finales acceder a los datos sin procedimientos sofisticados y sobre plataformas seguras».
Arcitecta. Otro de los problemas de la moderna gestión de datos es la colaboración en sistemas distribuídos a gran escala. De esto precisamente se ocupa Arcitecta con su producto MediaFlux, que se presenta como una compleja (no es un epíteto) plataforma para la orquestación de los datos en entornos que se caracterizan por grandes volúmenes de información. Aunque lleva diez años en el mercado, la compañía ha desarrollado su actividad básicamente en su país de origen, Australia, desde 1998. En Europa, presume de importantes referencias en Reino Unido, Alemania y Holanda. Para su estrategia de expansión – leit motiv del encuentro con la prensa europea – busca integradores, «con preferencia versátiles en cuanto a entornos de almacenamiento».
Desde sus orígenes, Arcitecta ha ido creciendo en proporción a la magnitud de los problemas que pretende resolver. Porque, según el razonamiento de Floyd Christopherson, su CMO afincado en San Francisco, «con el incremento del volumen de los datos también crece su segmentación» y, por consiguiente, la complejidad de hacerlos trabajar conjuntamente. ¿Cómo se puede decidir serenamente cualquier acción habiendo tantos silos y tantos tipos de datos y metadatos, tantos casos de uso, clasificaciones y tipos de almacenamiento?»
La causa del problema, según Christopherson, es que «bien por su naturaleza o por la propia infraestructura en la que residen, más pronto que tarde los datos acaban por ser incompatibles entre sí; esto es lo que favorece la creación de silos, y hace más difícil su gestión e incluso su acceso».
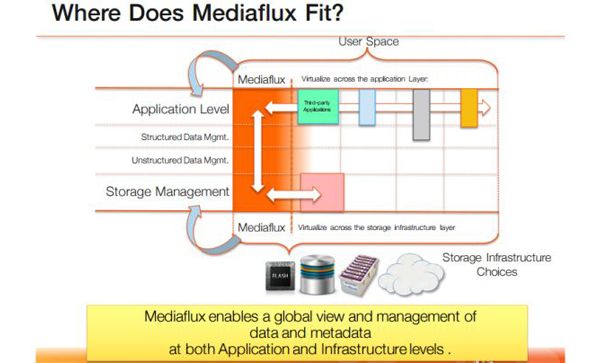
Mediaflux es una plataforma agnóstica en cuanto a las infraestructuras y poco intrusiva. que se instala por encima de los silos de datos, virtualiza el hardware a fin de facilitar el acceso y, en definitiva, «Ingiere, agrega y asegura la gestión de los datos en todos los formatos y en toda plataforma […] todo es compartible y accesible», resume el CMO de Arcitecta como colofón del encuentro con el grupo de periodistas.
Jut. Apurva Dave, un tipo de permanente buen humor, abrió la sesión con un argumento que ya es un lugar común en el ambiente californiano: «lo sepan o no, todas las empresas se están transformando en compañías de software y por esto mismo los datos son a un tiempo su mayor activo y su mayor preocupación». Una elocuente manera de introducir la plataforma analítica desarrollada por Jut, startup creada por Steve McCanne, antaño fundador de Riverbed que, en 2013, arrastró en la nueva aventura a varios miembros de su equipo anterior, entre ellos Dave como chief marketing officer.

Steve McCanne
La visita a las oficinas de Jut tuvo un contratiempo con final jocoso: una alarma de incendio en el edificio provocó que el grupo se trasladara a un jardín del Financial District, donde Dave continuó su discurso entre broma y broma. Las empresas raramente consiguen tener una visión holística de su software – predicaba el CMO – porque, para analizar los datos y tomar decisiones, dependen de sistemas de información que han ido formando silos; cada nueva necesidad que aparece, hace más difícil la correlación. O bien usan plataformas analíticas como Hadoop o Spark, etc, de manera que cada cambio exige nuevos desarrollos, con los inconvenientes que se pueden imaginar.
Recuperada la normalidad, de vuelta en sus oficinas, tomó la palabra McCanne: «hemos concebido una plataforma analítica del flujo de datos, unificada pero flexible, lo que facilita una visión única del conjunto de los datos, con el objetivo de abrir posibilidades casi infinitas de análisis». La solución combina el tratamiento in-memory en tiempo real con los datos almacenados en disco. Para ello, la clave está en su motor Jut Data Engine, que usa conectores o APIs para recuperar todos los flujos de datos en cualquiera de sus formatos. «Puede decirse que somos una mezcla de Google DataFlow y Tableau», sintetizó. Jut utiliza Cassandra como base de datos NoSQL y ElasticSearch como tecnología de búsqueda.
Es una solución ingeniosa, con la peculiaridad de su arquitectura mixta: el motor se instala on-premise y las aplicaciones se ejecutan en la nube de Jut. La idea es que el cliente pueda disponer en todo momento de la última actualización, sin necesidad de despliegues adicionales. El motor dispone de su propio lenguaje de scripting, Juttle, para definir los análisis y visualizaciones previas a la toma de decisiones. El producto de Jut está en fase beta y puede descargarse sin coste desde el site de la compañía. No hubo manera de saber cuándo se iniciará la comercialización. Quizá antes sea necesaria otra ronda de financiación.
[informe de Daniel Comino]